Delving into the Uncharted Realms of Llama 3.2
Meta has unveiled Llama 3.2, its latest stride in expansive language models, introducing unprecedented multimodal capabilities and heightened efficiency. This discourse explores the salient features, enhancements, and prospective applications of this cutting-edge AI model, poised to revolutionize the realm of artificial intelligence.
Introduction to Llama 3.2
Llama 3.2 marks Meta’s inaugural open-source AI model adept at processing both textual and visual data. This compilation spans from lightweight iterations suitable for edge devices to robust multimodal models capable of sophisticated reasoning tasks.
Quintessential Features and Enhancements
Multimodal Capabilities
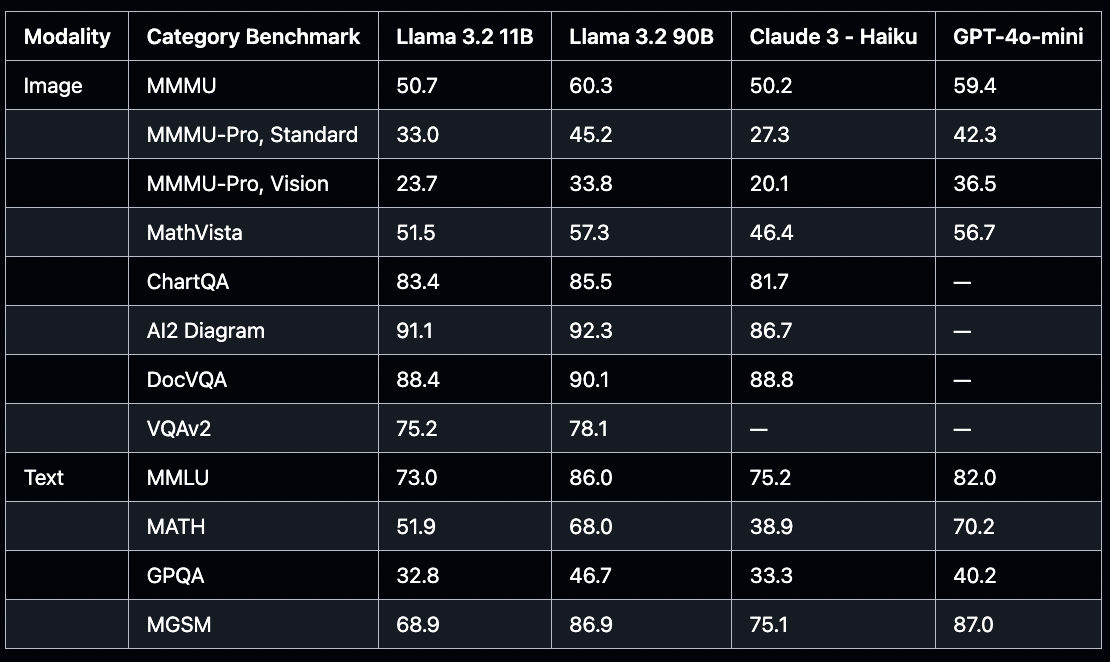
For the first time in the Llama lineage, the 11B and 90B models accommodate vision tasks. These models can:
Handle high-resolution images up to 1120x1120 pixels
Execute image captioning, visual reasoning, and document-centric visual question-answering
Incorporate image-text retrieval functionalities
Novel Model Dimensions
Llama 3.2 introduces four new models:
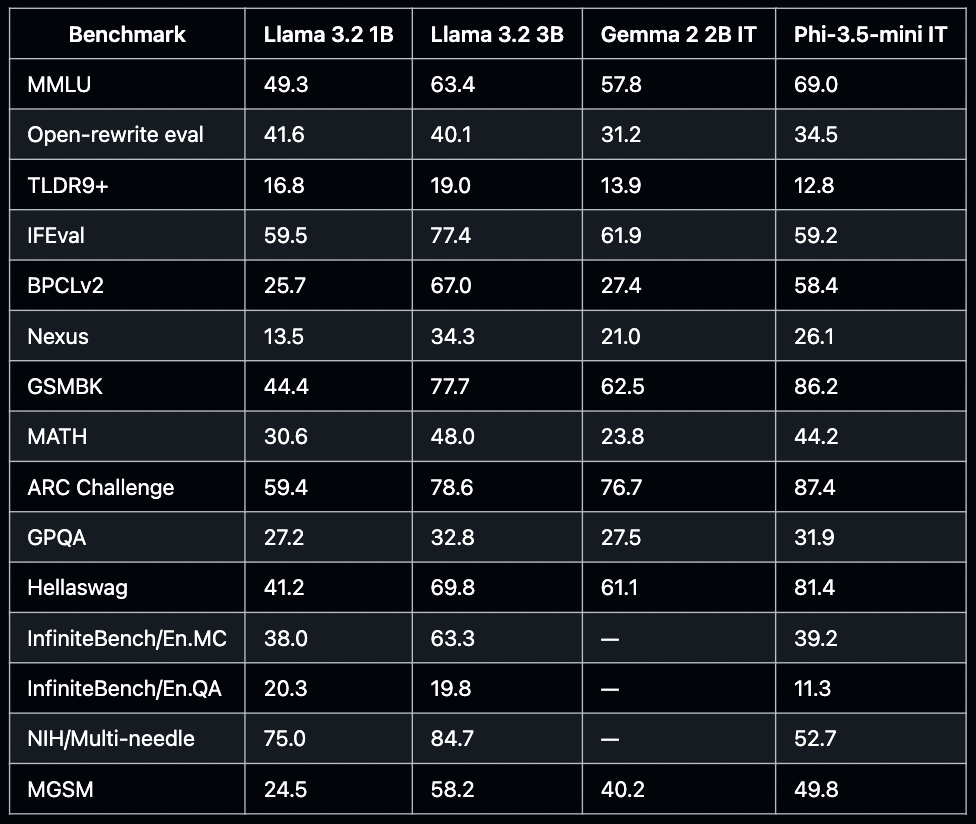
1B and 3B parameter models: Lightweight, text-only versions optimized for edge and mobile devices
11B and 90B parameter models: Enhanced versions endowed with vision capabilities

Despite their compact size, the new models exhibit impressive performance:
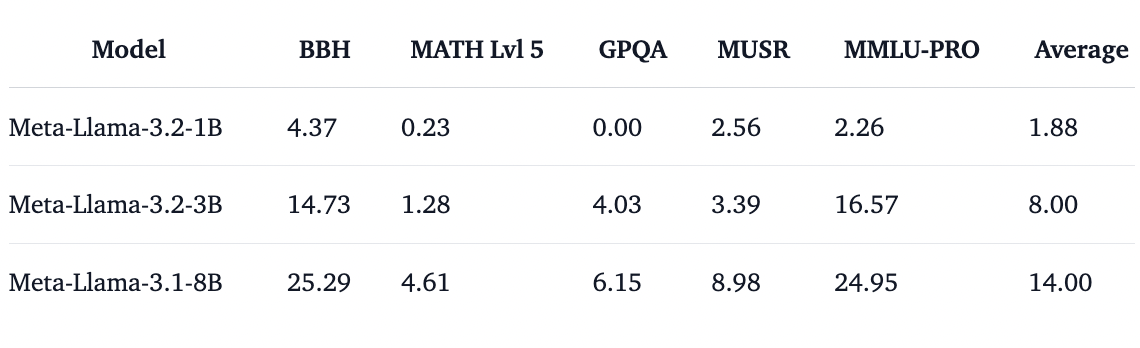
Architectural Innovations
Llama 3.2 incorporates significant architectural modifications for its vision models:
Contrasts Between Llama 3.2 and Llama 3.1
Here are the pivotal distinctions between Llama 3.2 and its predecessor, Llama 3.1:
1. Multimodal Capabilities
Llama 3.2 introduces multimodal models (11B and 90B) proficient in processing both text and images.
Tasks encompass image captioning, visual reasoning, and document visual question answering.
Llama 3.1 lacked these vision proficiencies.
2. New Lightweight Models
The 3B model in Llama 3.2 matches or exceeds Llama 3.1's 8B on summarization tasks.
The 1B model performs admirably on summarization and re-writing tasks, akin to larger models.
4. Architectural Modifications
- Llama 3.2 integrates a novel adapter architecture for vision models, merging image encoder representations.
5. Efficiency and Optimization
- Llama 3.2 offers reduced latency and improved performance, utilizing techniques like pruning and distillation.
6. Availability and Deployment
Llama 3.2 is accessible on platforms like Amazon Bedrock, Hugging Face, and Meta’s Llama website.
Meta introduced the Llama Stack Distribution for streamlined deployment.
7. Safety Features
- Includes the updated Llama Guard (Llama-Guard-3–11B-Vision) for moderating image-text inputs and outputs.
8. Context Length
- Both Llama 3.1 and 3.2 support a 128K token context length.
Efficiency and Optimization
Enhanced efficiency for AI workloads.
Techniques like pruning and distillation yield smaller, faster models.
Multilingual Proficiency
Llama 3.2 broadens its multilingual capabilities, officially supporting eight languages:
English
German
French
Italian
Portuguese
Hindi
Spanish
Thai
Vision Models
As the first Llama models capable of handling vision tasks, the 11B and 90B models necessitated a new architecture designed for image reasoning.
To enable image input, adapter weights were trained to integrate a pre-trained image encoder with the pre-trained language model. The adapter uses cross-attention layers to merge the image encoder’s representations into the language model. These adapters were trained on text-image pairs to align the image and text representations. While training the adapters, the image encoder parameters were updated, but the language model’s parameters remained unchanged to preserve its text-only capabilities, making it a seamless replacement for Llama 3.1 models.
The training process involved multiple stages, starting with pre-trained Llama 3.1 text models. Initially, image adapters and encoders were added and pre-trained on large-scale, noisy image-text pairs. Then, the models were trained on medium-scale, high-quality, domain-specific, and knowledge-enhanced image-text pairs.
For post-training, a similar approach to the text models was employed, involving alignment through supervised fine-tuning, rejection sampling, and direct preference optimization. Synthetic data generation played a crucial role, with the Llama 3.1 model filtering and augmenting questions and answers based on in-domain images. A reward model was used to rank candidate answers for fine-tuning data. Additionally, safety mitigation data was incorporated to ensure the model maintained a high level of safety while remaining helpful.
The final result is a set of models that can process both image and text prompts, allowing for a deeper understanding and reasoning of the combined inputs. This marks another step in enhancing Llama models with more advanced capabilities.
Lightweight Models
As discussed with Llama 3.1, powerful teacher models can be utilized to create smaller models with enhanced performance. The team applied two techniques—pruning and distillation—to the 1B and 3B models, making them the first highly capable, lightweight Llama models that can efficiently run on devices.
Pruning helped reduce the size of existing Llama models while retaining as much knowledge and performance as possible. For the 1B and 3B models, structured pruning was applied in a single-shot process from the Llama 3.1 8B model. This involved systematically removing parts of the network and adjusting weights and gradients to create a smaller, more efficient model that still maintained the original performance.
Knowledge distillation transfers knowledge from a larger model to a smaller one, allowing the smaller model to achieve better performance than training from scratch. For the 1B and 3B models in Llama 3.2, logits from the Llama 3.1 8B and 70B models were incorporated during the pre-training stage, where outputs (logits) from the larger models were used as token-level targets. After pruning, knowledge distillation was applied to further recover and improve the model’s performance.
Benchmarks
The instruct models were evaluated across three popular benchmarks that measure instruction-following and correlate well with the LMSYS Chatbot Arena: IFEval, AlpacaEval, and MixEval-Hard. These are the results for the base models, with Llama-3.1–8B included as a reference:
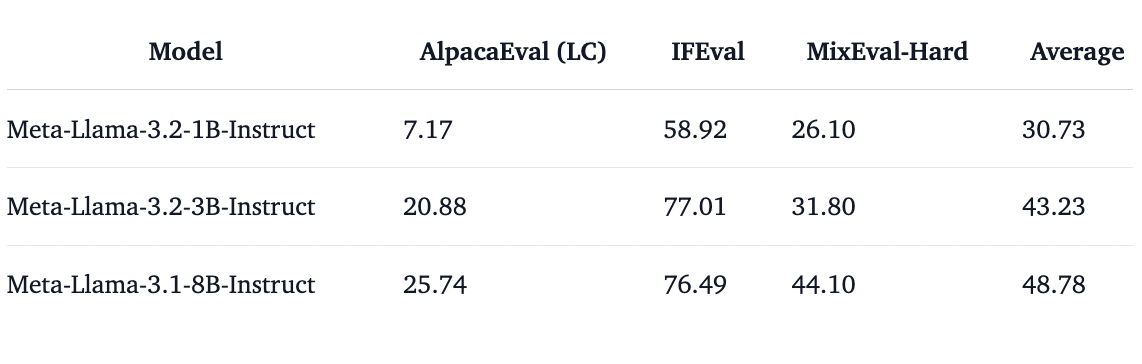
Remarkably, the 3B model is as strong as the 8B one on IFEval! This makes the model well-suited for agentic applications, where following instructions is crucial for improving reliability. This high IFEval score is exceedingly impressive for a model of this size.
How to Download and Run Llama 3.2 Locally
For this project, we are utilizing the Llama-3.2–1B-Instruct model on Mac.
Llama.cpp & Llama-cpp-python
Llama.cpp is the premier framework for cross-platform on-device machine learning inference. Meta provides quantized 4-bit and 8-bit weights for both the 1B and 3B models in this collection. The community is encouraged to embrace these models and create additional quantizations and fine-tunes. You can find all the quantized Llama 3.2 models here.
Installing Llama.cpp
To use these checkpoints with llama.cpp, you need to install it. Here’s how to install llama.cpp via Homebrew (works on Mac and Linux):
brew install llama.cpp
Running Llama 3.2 with Llama.cpp
Once installed, you can use the CLI to run a single generation or invoke the llama.cpp server, which is compatible with the OpenAI messages specification.
Running a Single Generation with CLI
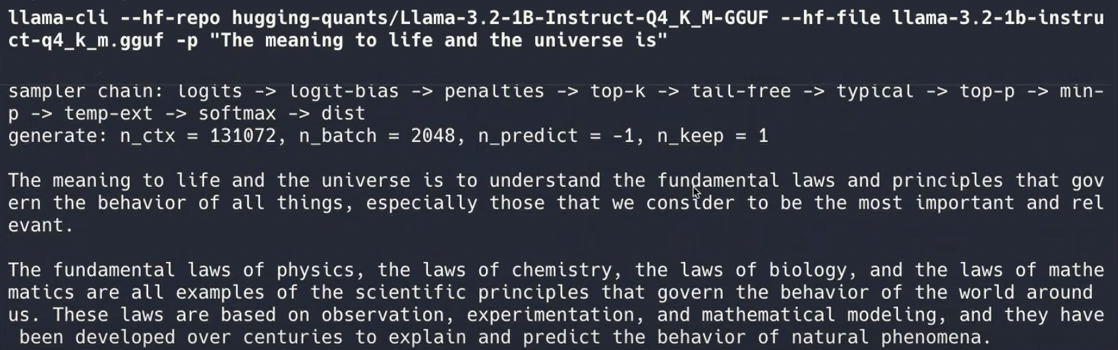
You can use the following command to generate text with Llama 3.2:
llama-cli --hf-repo hugging-quants/Llama-3.2-1B-Instruct-Q4_K_M-GGUF --hf-file llama-3.2-1b-instruct-q4_k_m.gguf -p "The meaning to life and the universe is"
Online Demonstration
You can experiment with the three Instruct models in the following demos:
Applications and Use Cases
Llama 3.2 is versatile, with potential applications such as:
Content Creation: High-quality text generation and image analysis for creative pursuits.
Visual AI Assistants: Build chatbots that comprehend and discuss visual content.
Document Analysis: Extract information from document images, receipts, and charts.
E-commerce: Enhance product descriptions and visual search capabilities.
Healthcare: Assist in medical image analysis and report generation.
Education: Create interactive learning experiences with text and visual elements.
Future Implications
Llama 3.2 represents a significant advancement in open-source AI:
It could lead to more sophisticated AI assistants capable of interpreting and generating both textual and visual content.
Its smaller models enable improved on-device AI applications.
It paves the way for advancements in multilingual and cross-modal AI understanding.
Conclusion
Llama 3.2 marks a monumental milestone in large language models. With its multimodal capabilities, enhanced efficiency, and superior performance, Meta has crafted powerful tools that can push the boundaries of AI. Whether you’re a developer, researcher, or business leader, leveraging the capabilities of Llama 3.2 could be pivotal in staying at the forefront of AI technology in 2024 and beyond.
References
Llama Models, "Llama 3.2 Model Card," GitHub, https://github.com/meta-llama/llama-models/blob/main/models/llama3_2/MODEL_CARD.md.
Hugging Face, "Llama 3.2 Vision 11B," Hugging Face, https://huggingface.co/spaces/huggingface-projects/llama-3.2-vision-11B.
Hugging Face, "Llama 3.2," Hugging Face, https://huggingface.co/blog/llama32.
Meta AI, "Llama 3.2 Connect 2024: Vision, Edge, and Mobile Devices," Meta AI, https://ai.meta.com/blog/llama-3-2-connect-2024-vision-edge-mobile-devices/.